Вам может быть любопытно, как новые поколения процессоров могут быть быстрее при тех же тактовых частотах, что и старые процессоры. Это просто изменения в физической архитектуре или что-то большее?
Почему, например, двухъядерный Core i5 с частотой 2,66 ГГц будет быстрее, чем Core 2 Duo с частотой 2,66 ГГц, который также является двухъядерным?
Это из-за новых инструкций, которые могут обрабатывать информацию за меньшее количество тактов? Какие ещё архитектурные изменения затронуты?

Почему процессоры нового поколения быстрее при той же тактовой частоте?
Обычно это не из-за новых инструкций. Это просто потому, что процессору требуется меньше циклов инструкций для выполнения тех же инструкций. Это может быть по большому количеству причин:
- Большие кеши означают меньше времени на ожидание памяти.
- Больше исполнительных единиц означает меньше времени на ожидание начала выполнения инструкции.
- Лучшее предсказание ветвления означает меньше времени, затрачиваемого на умозрительное выполнение инструкций, которые на самом деле никогда не нужно выполнять.
- Улучшения исполнительного модуля сокращают время ожидания выполнения инструкций.
- Более короткие конвейеры (pipeline) означают, что конвейеры заполняются быстрее.
И так далее.
Разработка процессора для обеспечения высокой производительности — это гораздо больше, чем просто увеличение тактовой частоты. Существует множество других способов повышения производительности, которые возможны благодаря закону Мура и играют важную роль в разработке современных процессоров.
Тактовая частота не может расти бесконечно
На первый взгляд может показаться, что процессор просто выполняет поток инструкций одну за другой, при этом производительность увеличивается за счёт более высоких тактовых частот. Однако одного лишь увеличения тактовой частоты недостаточно. Потребляемая мощность и тепловая мощность увеличиваются с увеличением тактовой частоты.
При очень высоких тактовых частотах необходимо значительное увеличение напряжения ядра процессора. Поскольку TDP увеличивается пропорционально квадрату Vcore, мы в конечном итоге достигаем точки, когда чрезмерное энергопотребление, тепловая мощность и требования к охлаждению предотвращают дальнейшее увеличение тактовой частоты. Этот предел был достигнут в 2004 году, во времена Pentium 4 Prescott. Хотя недавние улучшения в энергоэффективности помогли, значительное увеличение тактовой частоты уже невозможно.
График заводских тактовых частот современных ПК для энтузиастов за многие годы.

В соответствии с законом Мура, наблюдением, которое гласит, что количество транзисторов в интегральной схеме удваивается каждые 18–24 месяца, главным образом в результате уплотнения кристалла, были реализованы различные методы, повышающие производительность. Эти методы совершенствовались и совершенствовались на протяжении многих лет, что позволяет выполнять больше инструкций за определённый период времени. Эти методы обсуждаются ниже.
На первый взгляд последовательные потоки инструкций часто можно распараллелить
Хотя программа может просто состоять из серии инструкций, выполняемых одна за другой, эти инструкции или их части очень часто могут выполняться одновременно. Это называется параллелизмом на уровне инструкций (ILP). Использование ILP жизненно важно для достижения высокой производительности, и современные процессоры используют для этого множество методов.
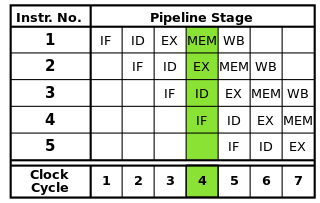
Конвейерная обработка разбивает инструкции на более мелкие части, которые могут выполняться параллельно
Каждую инструкцию можно разбить на последовательность шагов, каждый из которых выполняется отдельной частью процессора. Конвейерная обработка инструкций позволяет нескольким инструкциям проходить эти шаги одна за другой, не дожидаясь полного завершения каждой инструкции. Конвейерная обработка обеспечивает более высокие тактовые частоты: при выполнении одного шага каждой инструкции в каждом тактовом цикле для каждого цикла потребуется меньше времени, чем если бы целые инструкции должны были выполняться по одной за раз.
Классический конвейер RISC состоит из пяти этапов: выборка инструкций, декодирование инструкций, выполнение инструкций, доступ к памяти и обратная запись. Современные процессоры разбивают выполнение на множество этапов, создавая более глубокий конвейер с большим количеством этапов (и увеличивая достижимую тактовую частоту, поскольку каждый этап меньше и требует меньше времени для завершения), но эта модель должна обеспечить базовое понимание того, как работает конвейерная обработка.
Используются кэши для ускорения доступа к памяти
Современные процессоры могут выполнять инструкции и обрабатывать данные намного быстрее, чем к ним можно получить доступ в основной памяти. Когда процессору требуется доступ к ОЗУ, выполнение может приостанавливаться на длительные периоды времени, пока данные не станут доступными. Чтобы смягчить этот эффект, в процессор включены небольшие области высокоскоростной памяти, называемые кешами.
Из-за ограниченного пространства, доступного на кристалле процессора, кэши имеют очень ограниченный размер. Чтобы максимально использовать эту ограниченную емкость, кеши хранят только самые последние или часто используемые данные (временная локальность). Поскольку доступы к памяти имеют тенденцию группироваться в определенных областях (пространственной локальности), блоки данных рядом с тем, к чему недавно осуществлялся доступ, также хранятся в кэше. См .: Местоположение ссылки
Кеши также организованы на нескольких уровнях разного размера для оптимизации производительности, поскольку кеши большего размера, как правило, медленнее, чем кеши меньшего размера. Например, процессор может иметь кэш уровня 1 (L1) размером всего 32 КБ, в то время как его кэш уровня 3 (L3) может иметь размер в несколько мегабайт. Размер кеша, а также ассоциативность кеша, которая влияет на то, как процессор управляет заменой данных в полном кэше, значительно влияют на прирост производительности, получаемый с помощью кеша.
Итак, как эти методы со временем улучшают производительность процессора?
С годами конвейеры стали длиннее, что сократило время, необходимое для завершения каждого этапа, и, следовательно, позволило повысить тактовую частоту. Однако, помимо прочего, более длинные конвейеры увеличивают штраф за неправильное предсказание ветвления, поэтому конвейер не может быть слишком длинным. Пытаясь достичь очень высоких тактовых частот, процессор Pentium 4 использовал очень длинные конвейеры, до 31 ступени в Prescott. Чтобы уменьшить дефицит производительности, процессор будет пытаться выполнять инструкции, даже если они могут дать сбой, и будет продолжать попытки, пока они не достигнут успеха. Это привело к очень высокому энергопотреблению и снижению производительности, получаемой от гиперпоточности. Новые процессоры больше не используют конвейеры такой длины, особенно после того, как масштабирование тактовой частоты достигло предела; Haswell использует конвейер, длина которого варьируется от 14 до 19 этапов, а архитектуры с низким энергопотреблением используют более короткие конвейеры (Intel Atom Silvermont имеет от 12 до 14 этапов).
Точность предсказания ветвлений улучшилась с более продвинутыми архитектурами, уменьшив частоту сбросов конвейера, вызванных неверным предсказанием, и позволив одновременно выполнять больше инструкций. Учитывая длину конвейеров в современных процессорах, это критически важно для поддержания высокой производительности.
С увеличением бюджета транзисторов в процессор могут быть встроены более крупные и более эффективные кэши, что сокращает задержки из-за доступа к памяти. Доступ к памяти может потребовать более 200 циклов для выполнения в современных системах, поэтому важно максимально снизить потребность в доступе к основной памяти.
Новые процессоры могут лучше использовать преимущества ILP за счёт более продвинутой суперскалярной логики выполнения и «более широких» конструкций, которые позволяют одновременно декодировать и выполнять больше инструкций. Архитектура Haswell может декодировать четыре инструкции и выполнять 8 микроопераций за такт. Увеличение бюджета транзисторов позволяет включать в ядро процессора больше функциональных блоков, таких как целочисленные ALU. Ключевые структуры данных, используемые при неупорядоченном и суперскалярном выполнении, такие как станция резервирования, буфер переупорядочения и регистровый файл, расширены в новых конструкциях, что позволяет процессору искать более широкое окно инструкций для использования их ILP. Это основная движущая сила повышения производительности современных процессоров.
Более сложные инструкции включены в новые процессоры, и всё большее число приложений используют эти инструкции для повышения производительности. Достижения в технологии компиляторов, включая улучшения в выборе инструкций и автоматической векторизации, позволяют более эффективно использовать эти инструкции.
В дополнение к вышесказанному, большая интеграция частей, ранее внешних по отношению к ЦП, таких как северный мост, контроллер памяти и линии PCIe, сокращает ввод-вывод и задержку памяти. Это увеличивает пропускную способность за счёт сокращения простоев, вызванных задержками доступа к данным с других устройств.
Итак, новые поколения процессоров более производительны при тех же частотах потому что:
- Новый технологический процесс позволяет уменьшить тепловыделение, благодаря чему процессоры дольше могут работать на максимальных частотах.
- Увеличение количества ядер, благодаря чему увеличивается скорость за счёт параллельных вычислений.
- Добавляются новые комплексные инструкции процессора, увеличивающие его эффективность.
- Увеличение кэшей памяти, благодаря чему уменьшается задержка при получении данных для обработки.
- Меняется архитектура, логика обработки данных, становясь более эффективной.
- Контроллеры, мосты, дорожки становятся частью ЦП, что уменьшает задержку обмена данных.
- Другие устройства (оперативная память, видео карты, твердотельные диски) становятся быстрее, благодаря чему уменьшается время задержки поступления данных в процессор. То есть «Данные быстрее поступили» = «Результат вычисления готов быстрее».
Связанные статьи:
- Что означают суффиксы процессора Intel? (100%)
- Основы центральных процессоров: несколько процессоров, ядер и Hyper-Threading (100%)
- В чём разница между процессорами Intel Core i3, i5, i7, i9 и X? (100%)
- Процессоры Intel 10-го поколения: что нового и почему это важно (100%)
- Почему процессор AMD 5000 может превзойти процессоры Intel для игр (100%)
- Microsoft Copilot AI также появится в OneNote (RANDOM - 50%)